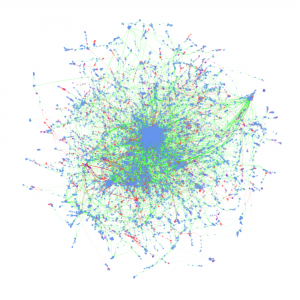




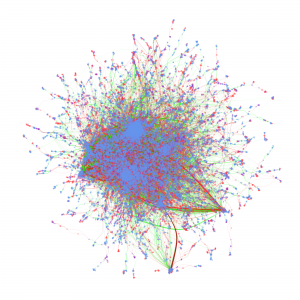


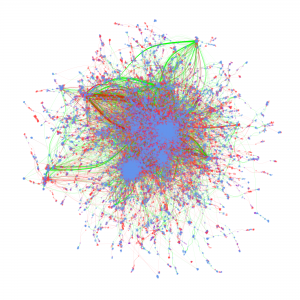

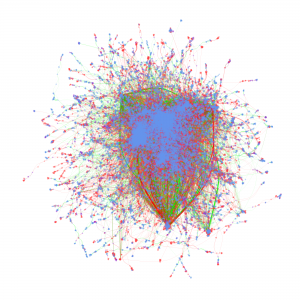

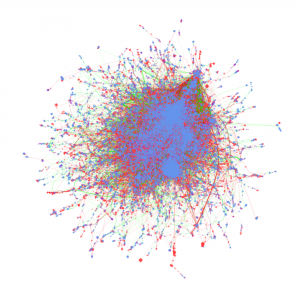
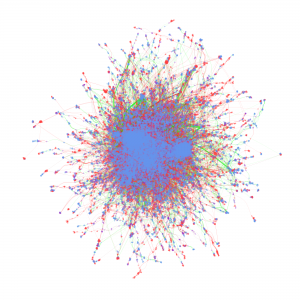
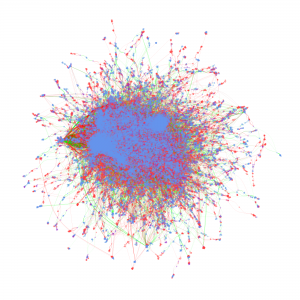
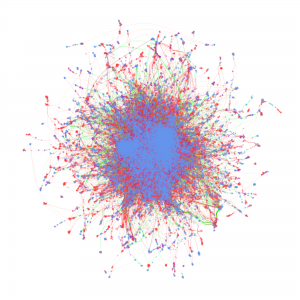

Cyberinfrastructure-Enabled Collaboration Networks (2016-2019)
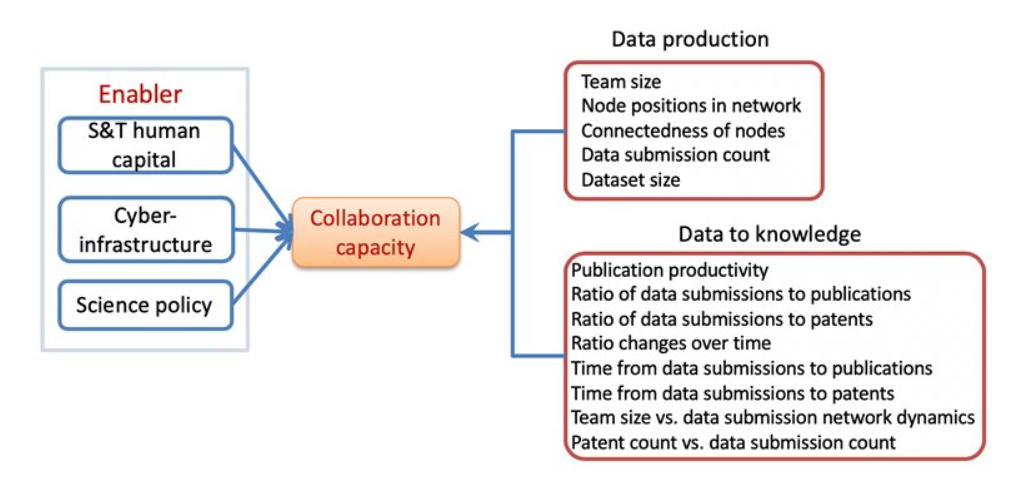
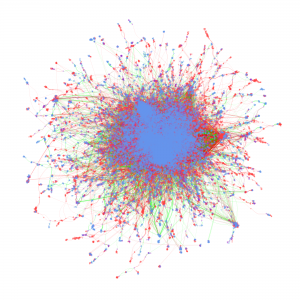
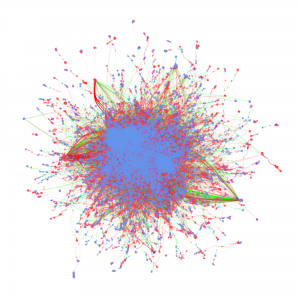
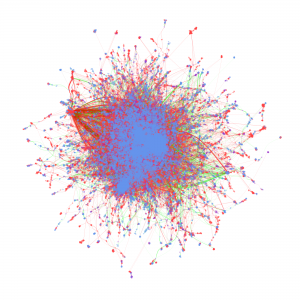
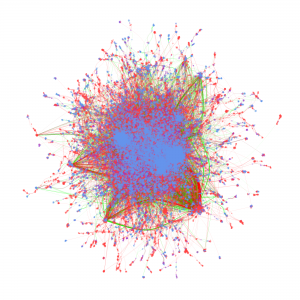
Cyberinfrastructure enables collaborative research and significantly impacts scientific capacity and knowledge diffusion. In response to the growing need for quantitatively evaluating outcomes and impact of federal investment on research, this project deploys new data, tools, metrics, and methods for assessing the impact of cyberinfrastructures and the data services built on them. This research helps researchers and policy makers understand how cyberinfrastructure affects collaboration dynamics and network structures of researchers. Datasets organized by longitudinal, thematic, topical, geographical, institutional, and author dimensions provided, which researchers, policy makers, and students can access and use to explore data-intensive science of science and innovation policy related research.
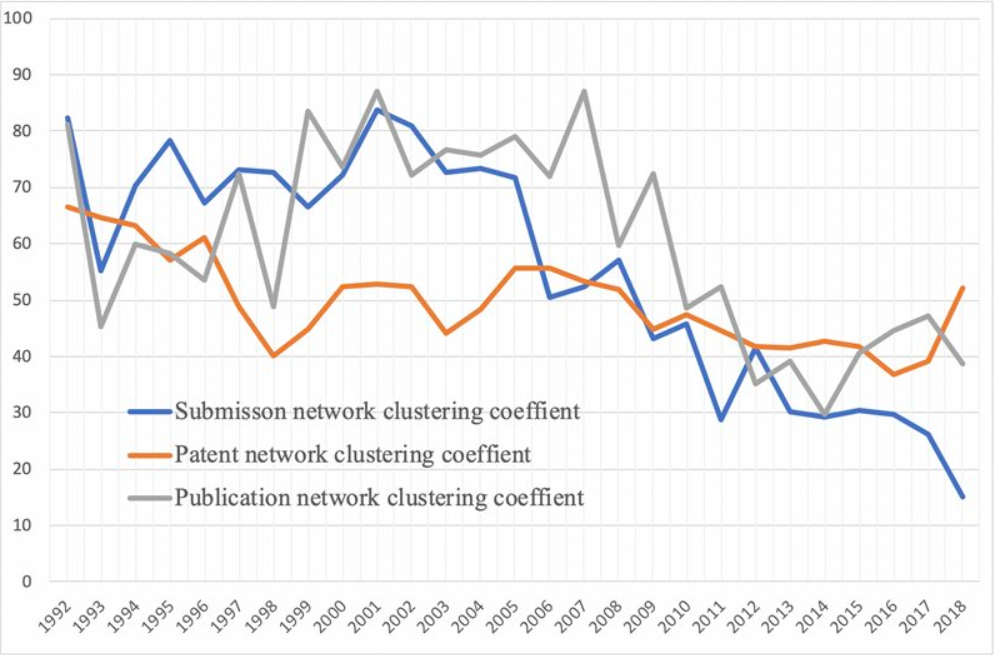
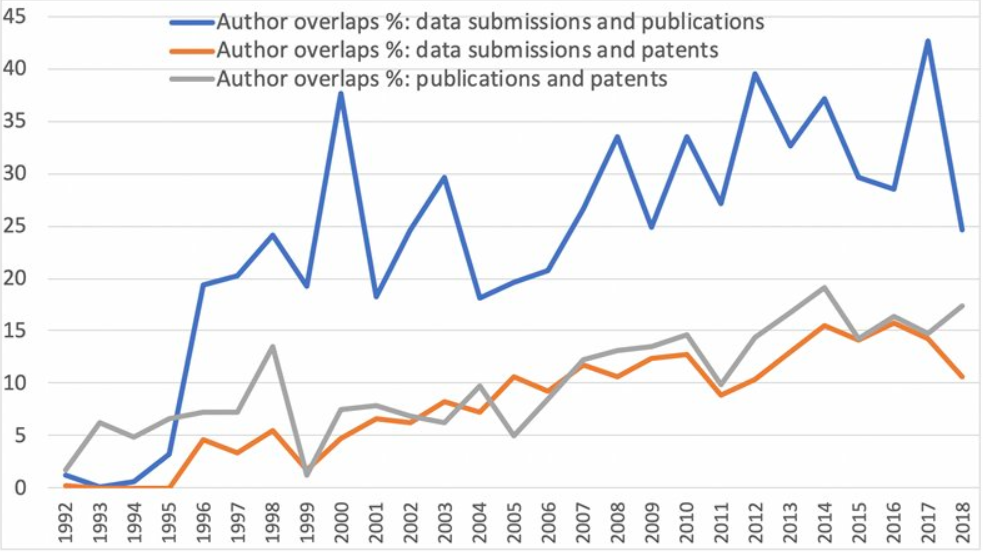
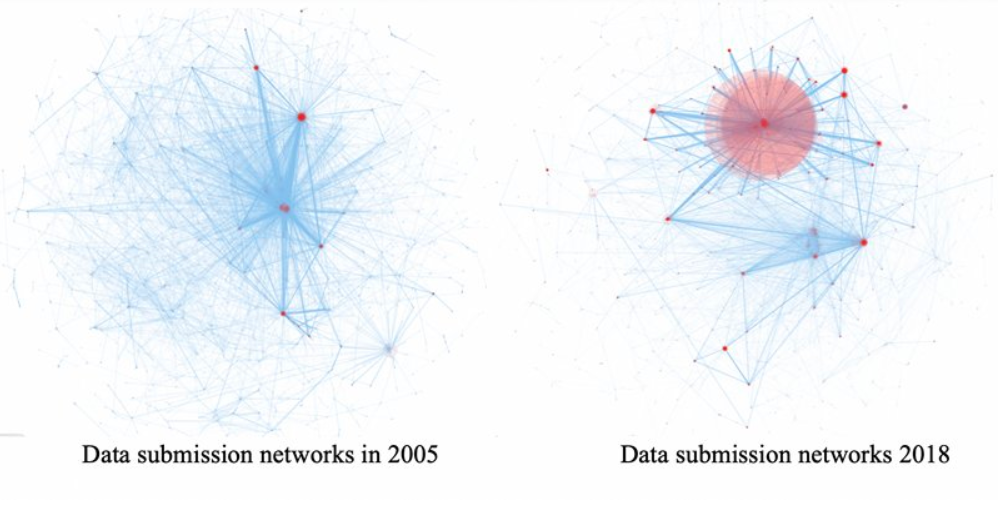
Metadata from GenBank, patent data from U.S. Patent and Trademark Office and funding data from NIH ExPORT are analyzed with descriptive statistics and models from Complex Network Analysis. The project not only examines the topological properties of the data submission and publication networks, but also the temporal ordering of collaborative relationships and the overlap of the sequence submission and publication networks. Through slicing, plotting, and visualizing data, appropriate sampling strategies and algorithms are developed to more deeply explore collaboration networks, both structurally and temporally. Algorithms used in community detection, machine learning, and visualization serve as primary computational methods in this research. Data products to be shared with research communities include 1) discovery lifecycle datasets containing sequence submissions, publications, and patents as well as the links between them and 2) funding factor datasets containing links between U.S. federal funding data and the discovery lifecycle datasets.
FUNDED BY: NIH/NIGMS
![]()
![]()